Code is the Lifeblood of LLMs
Why programmers remain essential in the AI era, while no-code tools fall short
Published on
-/- lines long
In the tech world, there's this idea that LLMs will remove the necessity for code and will replace programmers(opens in new tab). I think it's exactly the other way around:
-
AI empowers code and needs more code to do so, because text is the most efficient way to digitally express ideas.
-
Instead of obsoleting programmers, AI lowers the barriers to entry and allows anyone to become a programmer, and many people unknowingly already are.
No-code tools are inferior because UIs are not something that LLMs understand. On the other hand, anything represented by code can be training material for LLMs, allowing them to later generate solutions for it.
UIs are only useful for regular end-users of digital products, not the people building them. I believe that code will become the backbone of digital tools and as you'll see below, this movement has already begun.
Language of Logic
The following means nothing to a machine:
The sum of all even numbers from 1 to 100.
…and the following means nothing to a human:
01100100 01101001 01100100 01101110 00100111 01110100
00100000 01110000 01110101 01110100 00100000 01100001
00100000 01110010 01100101 01100001 01101100 00100000
01110000 01110010 01101111 01100111 01110010 01100001
01101101 00100000 01101000 01100101 01110010 01100101
00100000 01100010 01100101 01100011 01100001 01110101
01110011 01100101 00100000 01110100 01101000 01100101
00100000 01101111 01110101 01110100 01110000 01110101
01110100 00100000 01110111 01101111 01110101 01101100
01100100 00100000 01100010 01100101 00100000 01110100
01101111 01101111 00100000 01101100 01101111 01101110
01100111 00100000 01100110 01101111 01110010 00100000
01100001 00100000 01100010 01101100 01101111 01100111
00100000 01110000 01101111 01110011 01110100 00001010…but the following is understood by both machines and humans:
int sum = 0;
for (int i = 1; i <= 100; i++) {
if (i % 2 == 0) {
sum += i;
}
}All programming languages are abstractions over processor instructions and allow human thought to be translated into a machine-executable set of actions.
"Lower-level" languages(opens in new tab) (like Assembly(opens in new tab) and C(opens in new tab)) are closer to the machine side, while "higher-level" languages(opens in new tab) (like Python(opens in new tab) and JavaScript(opens in new tab)) are closer to the human side. However, they all boil down to a set of instructions executed by your device's CPU.
In other words, all programming languages are just different dialects of the grand language of logic, expressed as machine-readable text. A way to say when and how electricity should flow through an electric circuit.
Medium of Meaning
If we go further than code, text itself, regardless of language, is the simplest and most efficient way to represent meaning and ideas as something concrete.
We all know what a "chair" is and what it means (mostly(opens in new tab)). In Spanish, "silla(opens in new tab)" means the same thing. Both words would have the following representation in binary:
-
chair:
01100011 01101000 01100001 01101001 01110010 00001010 -
silla:
01110011 01101001 01101100 01101100 01100001 00001010
Basically, we have a way to represent an object used for sitting in New York and an object used for sitting in Madrid. In a machine-friendly way.
Sure, chairs can be used for many other things and in many other countries. But to get more specific, we just have to string together other words that have meaning in a similar way like "chair" does. As we form sentences and paragraphs, we develop an increasingly more vivid description of our ideas.
Superiority of Text
You might be wondering why we couldn't just use images or some other manner of expressing meaning. The answer is complexity. Look at this picture:
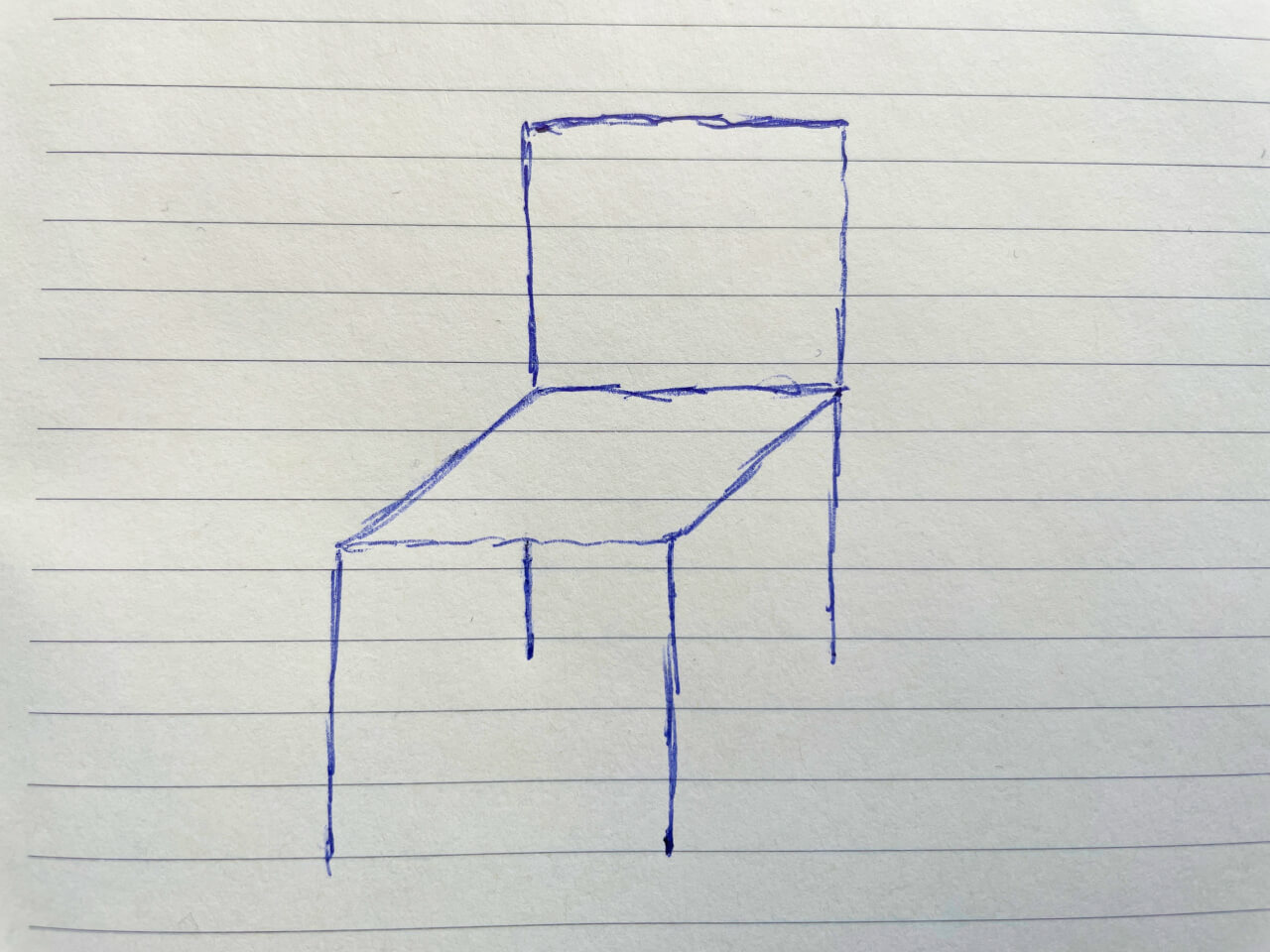
This looks like a chair. However, it's drawn on a piece of paper and is not an actual, physical chair, so it's also a drawing? It's not that detailed as well, so maybe it can be categorized as a sketch too? Or it could not be a chair at all. It could just be a bunch of blue lines? How do we know which of those is it?
On the machine side, this image is 160,968 bytes. That's over 32,000 times more than the required 5 bytes for the 5 characters in the word "chair." So we use way more data just to store a ton of ambiguity. With text, you use much less space to encode not one, but two concrete things:
-
A single object or idea
-
The language it relates to
In the case of the image, there's a lot of stuff going on and we can't be sure if we even have a chair in the first place! We can't even know if a gentleman is talking about it or a señor…
Sure, we can shrink it down and remove some of the detail, so it can be more specific. Perhaps store it as a 16x16 image with just a few black lines:

However, that can still be ambiguous, at least for machines. It can be a chair, but it can also be two tables glued together. Or just random black lines. It also continues to be inefficient in terms of storage, as you need to store data for all those 256 pixels. When exported as PNG(opens in new tab), the image is 217 bytes. Still way more than the 5 bytes required for "chair."
Perhaps we could somehow shrink the image down even more, while preserving legibility and decreasing file size? Well, we would just end up reinventing pictographs(opens in new tab):
Most of the oldest characters are pictographs (象形; xiàngxíng), representational pictures of physical objects. Examples include 日 ('Sun'), 月 ('Moon'), and 木 ('tree').
Here's the simplification process for "mountain" (shān; 山):
On the machine side, it seems like pictographs could be superior to words, since an entire object is represented by a single character, right? Well, each Chinese character, for example, takes 3 bytes to be stored when encoded with UTF-8(opens in new tab). This can be more efficient, but not always:
-
mountain: 8 chars, 8 bytes;山(shān): 1 char, 3 bytes 🏆 -
chair: 5 chars, 5 bytes 🏆;椅子(yǐzi): 2 chars, 6 bytes
As you can see, in computing terms, it probably wouldn't make much of a difference, so let's talk about the human point of view. Have you ever tried learning Chinese? It's way more difficult to memorize thousands of distinct characters than it is to memorize only 26 and just combine them in different ways.
Regardless, even if we start with images, we end up with some form of text characters anyways. It's the most efficient way to encode meaning, both for humans and machines.
LLMs as Compilers
Now that you know why text is so efficient, it becomes clear why code is so powerful too. It's essentially a dialect of English, where you combine specific key words and characters in predictable ways in order to represent logic. The main difference is that it's also understood by machines.
That's why LLMs are so useful — they allow you to translate logic from regular English to "machine-friendly English." A lot similar to how gcc(opens in new tab) allows you to translate that machine-friendly English (code written in C) to actual executable binary code.
In a way, LLMs turn English itself into the highest-level programming language. However, the cost of this extra layer of abstraction is the loss of control. When it comes to code, the devil is in the details, as a single misplaced character can result in fatal errors and unintended behaviors, and AI hallucinates(opens in new tab) a lot. This means that unless you understand what happens at the lower levels, you won't be able to tweak neither the code, nor the higher-level AI prompt that generated it.
Here's how LLMs would compare to programming languages in terms of control and ease of use:
As you can see, there's nothing in the top-right corner. There's nothing that gives you both total control and ease of use. And there never will be! Why? Because as you increase complexity, you also increase the necessary level of detail. You can't ask AI to "create a good-looking shopping website" — the same way you can't boil down a 400-page novel to a single sentence.
Okay, you can boil down an entire novel to a single sentence, but it would no longer be what it's meant to be. With no story or emotion, you wouldn't be moved by it. Similarly, you can shrink down a high-resolution photo to a 10x10 speck of pixels, but it would just be an unintelligible colored square. So simply asking for a "good-looking shopping website" would amount to nothing more than a mediocre, soulless, and unusable boring page.
Exceptional products and works of art have tons of hidden complexity and there's no getting away from that. Although AI can improve and learn to handle it, we would still need to have a deeper understanding for when things inevitably don't go down as expected. This constantly happens when working with humans. How could working with AI be different, especially when trained on our own faulty views of the world? Sure, we could just feed it absolute truths, but who knows where and how to find them? God?
Yes-Code Tools
Amazon Web Services (AWS)(opens in new tab) is the most popular cloud provider in the world and handles all things tech. It has a very detailed web console that allows you to set up networks, servers, databases, and all of their different settings.
Here's what you see when you're setting up a new server:
You can configure literally anything you want with just point-and-click! That's an example of a no-code solution(opens in new tab).
However, infrastructure as code (IaC(opens in new tab)) has gotten a lot more popular in recent years, thanks to tools like Terraform(opens in new tab). It's not only preferred by senior DevOps engineers but is actually considered best practice! That's right, these lunatics willingly ditch the comfortable UIs and laboriously type on a keyboard!?
With Terraform, you use code to express the desired state of the infrastructure you want. To create a server, you simply write:
resource "aws_instance" "my_server" {
ami = "ami-0dcc1e21636832c5d"
instance_type = "m5.large"
}…and that's it!
Of course, it gets exponentially more complex as you get into more sophisticated architecture, but the idea is that code allows you to express desired states and outcomes through the power of text. This is important because an LLM can be trained on that same text to give you solutions!
If I ask ChatGPT to "give me the cheapest AWS server with Terraform", it'll gladly do so:
provider "aws" {
region = "us-east-1" # You can change the region if needed
}
resource "aws_instance" "cheapest_instance" {
ami = "ami-08c40ec9ead489470" # Amazon Linux 2 AMI ID for us-east-1
instance_type = "t2.micro" # Cheapest instance
tags = {
Name = "cheapest-ec2-instance"
}
# Optionally, add a security group to allow SSH access (port 22)
security_groups = ["default"]
# Optionally, add key pair to allow SSH access
key_name = "your-key-name" # Replace with your SSH key
}
# Output the public IP
output "instance_ip" {
value = aws_instance.cheapest_instance.public_ip
}On the other hand, if there was no Terraform, there wouldn't have been a way to use code to provision infrastructure and GPT would've been pretty much useless. Why? It's way more complex for it to log into my AWS account and click tens of times at the right places at the right times under the right conditions. GPT would need to figure out what every single button in the AWS console does and what the surrounding text means. It's just too unnecessarily ambiguous and complicated, like the chair drawing I showed earlier.
By expressing complexity as text (code), we build a brigde that LLMs can walk over to develop understanding of our problems and give us solutions to them in a way that UIs can't. Furthermore, we can share that text on the web, like on GitHub and Stack Overflow, and not only help each other, but provide even more context for AI in the process.
Conclusion
LLMs won't make programmers obsolete. Quite the opposite. They allow anyone to be a programmer by lowering the barriers to entry and turning English itself into a kind of programming language.
However, the problem is that the details get abstracted away, and they're the key to making things that are actually useful and enjoyable. The only way around that is to have deeper knowledge of what's beneath, be it to write better prompts or to tinker with the code itself.
Since code is the most efficient bridge between human logic and machines, people that understand code and tools that operate with code will be superior, and will benefit the most from AI.